PSD - Dr Nicolás Hernández
| No. | Project Title | Funding Notes |
|---|---|---|
| Project 1 | Empowering Causal Inference with Functional Data Analysis | New Talent/CSC/EPSRC/Underrepresented/self-funded |
| Project 2 | Advanced Inference methods for High-Dimensional and Functional Data | CSC/EPSRC/Underrepresented/self-funded |
| Project 3 | Signature-Based Forecasting of Functional Time Series | CSC/EPSRC/Underrepresented/self-funded |
| Project 4 | Advanced Modelling and Forecasting of Functional Time Series | CSC/Underrepresented/self-funded |
1. Empowering Causal Inference with Functional Data Analysis
Supervisor: Dr Nicolás Hernández
Project description:
Modern observational studies, particularly in healthcare and energy, are increasingly characterized by high-dimensional longitudinal data, where information is recorded almost continuously (e.g., patient biomarker trajectories, household energy consumption profiles). Functional Data Analysis (FDA) provides a powerful statistical framework to treat these entire time series or curves as single units of data, inherently capturing dependencies and shape information.
However, applying traditional Causal Inference (CI) methods to this complex, high-dimensional setting is challenging, as classical approaches often suffer from unstable estimates due to time- varying confounding, restrictive linearity assumptions, and inadequate handling of irregularly measured or sparse data. The connection between CI and FDA is an underdeveloped, yet critical, area of research. This project is motivated by the urgent need for robust, trustworthy, and computationally efficient statistical methodology to reliably quantify causal effects from such complex observational data, directly addressing challenges in assessing interventions for healthcare and energy decarbonisation.
Research Objectives:
This Ph.D. project will be embedded within the larger research program on Functional Causal Inference (FDA-CI), led by the First Supervisor (Dr. Hernández). The core objectives for the Ph.D. research are:
O1- Theoretical Derivations for Functional Inference: To support the main grant objectives by proving the Bernstein-von Mises theorem for the proposed Causal FGAM. This is the ultimate theoretical goal, which is necessary for justifying the construction of credible bands with valid frequentist coverage properties, a key requirement for reliable inference in this setting.
O2- Computational Validation and Inference: To design and execute extensive Monte Carlo simulation studies for the newly developed FDA-CI methodologies, specifically the Causal Functional Generalized Additive Model (FGAM) for binary treatments and the FGAM for continuous functional interventions. This includes validating the theoretical properties (e.g., posterior consistency and contraction rates) and constructing simultaneous credible bands for quantifying uncertainty across the entire functional domain.
O3- Methodological Implementation: To implement and empirically study the novel weighted reconstruction operator theory for counterfactual estimation from partially observed functional data. This involves leveraging functional logistic regression to estimate propensity scores and applying Inverse Probability of Censoring Weights to correct for selection bias in the counterfactual reconstruction.
O4- Open-Source Software Development: To lead the development and release of a comprehensive, fully documented open-source R software package that makes the novel FDA-CI methods accessible to the wider research community.
O5- High-Impact Application: To apply the developed methodologies to real-world, high-impact case studies, specifically focusing on the NHS, Optima Partners, and Arcturis collaborations.
Expected Contributions
- Theoretical Validation: Rigorous empirical validation of new statistical theory (posterior consistency, contraction rates) for Functional Causal Inference via extensive simulation studies.
- Computational Methodology: Novel implementations and comparisons of key functional causal estimators (FATE, FATT, FADRF, weighted reconstruction) within a high-performance computing environment.
- Open-Source Tooling: A user-friendly, fully documented R package that makes state-of-the-art FDA-CI methods accessible to applied researchers, accelerating scientific progress.
- High-Quality Publications: Submission of at least two first-author papers based on
- the methodologies and one paper focusing on the high-impact applications.
Student Profile
The applicant should have a strong background (e.g., Master’s degree) in statistics, machine learning, or a closely related quantitative field. The applicant’s research interests must align with one or more of the core areas of the project: functional data analysis, statistical inference, and high-dimensional statistics. Since the project involves extensive computational work, including Monte Carlo studies and the development of an open-source R package, strong programming skills (e.g., in R, Python) are highly desirable
Supervisory Environment
The Ph.D. project will be situated in an ideal research environment at Queen Mary University of London (QMUL). The student will be jointly supervised by Dr. Nicolás Hernández and Dr. Eftychia Solea. Dr. Nicolás Hernández is lecturer in Statistics, whose research is oriented to develop statistical and machine learning methods to tackle inferential problems in high-dimensional and functional data over diverse fields such as health, finance, and genetics.
Dr. Hernández’s work has mainly focused on predictive confidence bands for functional time series and domain selection and classification in the functional data context. Dr. Eftychia Solea (Lecturer in Statistics), whose primary research interest lies in developing statistical methodologies for analyzing random functions (mathematical curves) and designing efficient algorithms for their practical implementation. In particular, Dr. Solea has published work on graphical models, dimension reduction, quantile regression, and causal inference for functional data, including recent work in distributional data analysis.
References: References-Nico-CIFDA [PDF 98KB]
Funding Notes:
1. This project is open to candidates applying for New Talent/CSC/EPSRC/Underrepresented Studentships and self-funded candidates.
2. New Talent Research Enabling Scheme => 3 years stipend and Home tuition fees. Students with International fee status are required to cover the difference between Overseas and Home fees. Stipend at QMUL rate (c.£21,874 p.a. full-time, £10,937 part-time for 2025/26; 2026-27 tbc)
Further information:
How to apply
Entry requirements
Fees and funding
PhD Information Session 2026:
On Wednesday 14 January, we will be holding a short information session about PhD studies in Mathematics at QMUL. For full details about the event, please visit: https://www.qmul.ac.uk/maths/postgraduate/postgraduate-research/phd-information-session-2026/
2. Advanced Inference Methods for High-Dimensional and Functional Data
Supervisor: Dr Nicolás Hernández
Project description:
In recent years there has been a deluge of population level data arising from far ranging fields. Near-infrared (NIR) spectra samples consist of numerous overlapping absorption bands, each corresponding to different vibrational modes of the molecular components. These vibrations are highly sensitive to the physical and chemical properties of the compounds involved. As a result, spectroscopic data exhibit a strongly correlated structure due to the complex nature of spectral absorption bands, with underlying information changing smoothly across wavelengths. This characteristic distinguishes spectral data from typical high-dimensional statistical data.
These large collections of complex data, popularly denominated as Big–Data, must be represented necessarily in a coordinate spaces of high dimensions and require sophisticated analytical techniques to be transformed in valuable information. This type of data can be embedded in what is called nowadays: Functional Data. In this context, one promising research avenue is the development of novel methodologies to make robust inference for this type of data.
Traditionally, spectral data analysis has mainly relied on multivariate techniques such as partial least squares (PLS) regression, given its capability of dealing with high-dimensional and correlated datasets effectively. However, this method treats spectra as a series of discrete variables rather than as a continuous function. From a physical standpoint, it is more meaningful to view the spectrum as a smooth function, composed of absorption peaks that reflect the various chemical constituents in the sample, where the absorbance at nearby wavelengths is strongly correlated. In this sense Functional Partial Least Squares (FPLS) regression models are an extension of PLS regression designed for handling functional data. The key idea behind FPLS is to generalize the PLS approach to a functional setting, allowing the extraction of relevant components from high-dimensional functional data.
The main objectives of this projects are:
- Develop computationally efficient models for domain selection in the FPLS context: Interval Partial Least-Squares Regression (iPLS) is an adaptation of PLS tailored for high-dimensional spectral data, such as Near-infrared spectra. Spectrometric data is expressed over a continuous domain, therefore interval selection is a more viable alternative for feature extraction than variable selection. Despite its potential, a primary challenge in iPLS remains in the selection of optimal intervals. Although traditional approaches, such as forward and backward selection methods, have practical benefits, they have crucial limitations of heavy reliance on heuristic approaches. This task aims to propose a novel approach to interval selection in iPLS via history matching, a statistical method for calibrating complex computer models, and uncertainty quantification techniques. Gaussian Process Regression or Stochastic Partial Differential Equations (SPDE) could be used as an emulator, emphasising its ability for flexible modelling and its provision of uncertainty estimates. This integration aims to optimise the accuracy of interval selection by utilising implausibility measures to highlight discrepancies between model predictions and observations.
- Ordinal data is a specific type of categorical data where the categories have a natural order. This type of data is common in real-world applications, such as in Food Quality Assessment. In food quality control, NIR (near-infrared) spectroscopy is used to measure properties of products like wine or olive oil. The spectrometric data could be classified into quality ordinal categories such as, Premium (High Quality), Standard (Medium Quality) and Below Standard (and Low Quality). However, practitioners often misinterpret this data, either treating it as quantitative by assigning integer values to the categories or ignoring the order altogether and treating it as nominal data. Given the importance of FPLS in the Analysis of Spectroscopic Data and the relevance of ordinal data in the field, is key to develop an appropriate model for this type of setting.
Student Profile
The applicant should have a strong background (e.g., Master’s degree) in statistics, machine learning, or a closely related quantitative field. The applicant’s research interests must align with one or more of the core areas of the project: functional data analysis, statistical inference, and high-dimensional statistics. Strong programming skills (e.g., in R, Python) are highly desirable.
Supervisory Environment
The student will be jointly supervised by Dr. Nicolás Hernández (Lecturer in Statistics) whose research is oriented to develop statistical and machine learning methods to tackle inferential problems in high-dimensional and functional data over diverse fields such as health, finance, and genetics.
References: References-Nico-InfereceFDA [PDF 109KB]
Funding Notes:
This project is open to candidates applying for CSC/EPSRC/Underrepresented Studentships and self-funded candidates.
Further information:
How to apply
Entry requirements
Fees and funding
PhD Information Session 2026:
On Wednesday 14 January, we will be holding a short information session about PhD studies in Mathematics at QMUL. For full details about the event, please visit: https://www.qmul.ac.uk/maths/postgraduate/postgraduate-research/phd-information-session-2026/
3. Signature-Based Forecasting of Functional Time Series
Supervisor: Dr Nicolás Hernández
Project description:
Functional time series (FTS) models have become central to the statistical analysis of temporally indexed curves, such as climate profiles, energy consumption curves, or spectrometric data. The most classical framework is the Autoregressive Hilbertian process (ARH(p)), introduced by Bosq (2000), which models a sequence of random functions Xt ∈ L_2([0, 1]) via
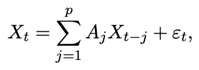
where each A_j is a bounded linear operator on the Hilbert space.
Despite its elegance, the ARH framework remains essentially linear. In contrast, the signature transform from rough path theory (Lyons, 1998) provides a nonlinear, universal, and coordinate-free representation of paths, with established applications in machine learning and stochastic analysis.
The proposed research aims to build a rigorous bridge between these two domains by developing a signature-based autoregressive model for functional time series, combining the interpretability of ARH processes with the expressivity of signature features.
Research Objectives
O1. Theoretical foundation: Define and study a class of Signature Autoregressive Hilbertian (SigARH) processes, of the form
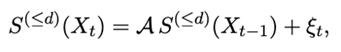
where S(≤d)(Xt) denotes the truncated signature of Xt up to order d. Existence, stationarity, and uniqueness will be analyzed in tensor algebra.
O2. Statistical inference: Develop estimation procedures for the operator A based on empirical data, analyze identifiability, and derive convergence rates for the estimated forecast operator as T → ∞.
O3. Computational methodology: Build efficient numerical algorithms for large-scale FTS forecasting using signature features, exploiting dimension reduction via functional bases (Fourier, FPCA, wavelets) and regularized regression techniques.
O4. Applications and validation: Evaluate the proposed approach on both synthetic and real-world functional datasets (e.g., temperature curves, energy demand profiles, or financial trajectories) and compare against standard ARH and kernel methods.
Expected Contributions
- A unified theoretical framework for Signature-based Functional Time Series.
- New statistical estimators with asymptotic guarantees.
- Computational tools for high-dimensional FTS forecasting.
- Benchmark studies demonstrating performance improvements over ARH.
Applicant profile
The ideal PhD applicant must possess a Master’s degree in a quantitative discipline such as Statistics, Machine Learning, or Applied Mathematics. Critical to success is a research interest alignment with Functional Data Analysis (FDA), Statistical Inference, and High-Dimensional Statistics. Knowledge of rough path theory and the signature transform is desirable. Due to the project’s computational scope, which includes extensive Monte Carlo studies and the development of an open-source R package, the candidate must demonstrate strong programming skills in R or Python, ideally with experience using C++ interfaces for high-performance computing on large-scale datasets
Supervisory Environment
The project will be hosted in the School of Maths at Queen Mary University combining expertise in:
- Functional data analysis and stochastic processes,
- Geometric and statistical machine learning,
- Scientific computing and data-driven modeling.
It would be possible to secure funds for a research stay at the ERIC Lab - University Lumière Lyon 2, allowing the student to collaborate directly with the co-supervisor and leverage the expertise and research environment there. This offers an invaluable opportunity for international collaboration and exposure to diverse perspectives in the field.
References: References-Nico-SigFTS [PDF 98KB]
Funding Notes:
This project is open to candidates applying for CSC/EPSRC/Underrepresented Studentships and self-funded candidates.
Further information:
How to apply
Entry requirements
Fees and funding
PhD Information Session 2026:
On Wednesday 14 January, we will be holding a short information session about PhD studies in Mathematics at QMUL. For full details about the event, please visit: https://www.qmul.ac.uk/maths/postgraduate/postgraduate-research/phd-information-session-2026/
4. Advanced Modelling and Forecasting of Functional Time Series
Supervisor: Dr Nicolás Hernández
Project description:
Functional Time Series (FTS) models provide a powerful framework for analyzing data represented as temporally indexed curves, essential in applications like energy demand forecasting and environmental monitoring. FTS data are commonly constructed by segmenting a (seasonal) univariate time series into regular intervals (slicing). We define the slicing window, ω, as the length (or number of observation points) of the interval used to define each
functional observation Zn(t), where t ∈ [0, ω].
This common segmentation practice introduces two critical challenges that must be addressed for robust modeling and inference:
- Optimal Slicing Window (ω): Determining the ideal length and position of the interval is paramount. An arbitrary or poorly chosen slice can lead to inconsistent functional representations, potentially violating the core FTS assumption that the curves belong to a separable Hilbert space, and ultimately degrading model performance. It is almost customary in practice, to slice the time series in terms of subjective or a priori selected calendar measures (days, weeks, etc.) rather than in terms of model accuracy or objective statistical metrics. This research line also aims to provide an answer to the fundamental and crucial question of when a univariate time series approach is preferable to a functional time series approach.
- Boundary Dependency: Slicing introduces an artificial temporal dependence between the start of one curve and the end of the previous curve. This biases the estimation of the functional auto-covariance operator and compromises the specification of the underlying FTS models, particularly affecting model selection procedures and the estimation of coefficients in models like ARH(p).
Research Objectives
O1 Theoretical Derivations for Optimal Slicing: To develop a data-driven methodology for selecting the optimal slicing window, ω∗, by formally proving its link to minimizing the mean squared error (MSE) of the functional observations around the mean function, which ensures the most parsimonious functional representation. We seek to establish this criterion via the functional norm:

This includes establishing the conditions under which ω∗ remains optimal for complex FTS forecasting models, such as the ARH(p) framework.
O2 Computational Validation and Inference: To design and execute extensive Monte Carlo simulation studies comparing key FTS models (specifically ARH(p) and FPCA-based models) using different slices against univariate benchmarks (ARIMA). This validation will rigorously determine if the FTS approach, when optimally sliced, maintains superior forecasting error across various horizons (h).
O3 Methodological Implementation and Artifact Mitigation: To implement and empirically study novel techniques for mitigating slicing artifacts, specifically:
- A domain selection strategy based on a functional divergence criterion (e.g., a metric on the auto-covariance operator) for boundary removal.
- The use of a pre-whitening transformation (based on residuals from a low-order ARH model) to reduce boundary-induced autocorrelation bias.
O4 Open-Source Software Development: To lead the development and release of a comprehensive, fully documented open-source R package that makes the novel optimal slicing and artifact mitigation methodologies accessible to the wider research community.
O5 High-Impact Application: To apply the developed methodologies to real-world, high-impact case studies, including data from energy demand forecasting (e.g., half-hourly electricity demand), environmental monitoring, and traffic analysis, with the goal of publishing findings in high-impact statistical journals (e.g., IJF, JASA, JRSS-B)
Student Profile
The applicant should have a strong background (e.g., Master’s degree) in statistics, machine learning, or a closely related quantitative field. The applicant’s research interests must align with one or more of the core areas of the project: Time series, functional data analysis, statistical inference, and high-dimensional statistics. Strong programming skills (e.g., in R, Python) are highly desirable.
Supervisory Environment
The student will be jointly supervised by Dr. Nicolás Hernández and Dr. Antonio Elias. Dr. Nicolás Hernández (Lecturer in Statistics) whose research is oriented to develop statistical and machine learning methods to tackle inferential problems in high-dimensional and functional data over diverse fields such as health, finance, and genetics. Dr. Hernández’s work has mainly focused on predictive confidence bands for functional time series and domain selection and classification in the functional data context. Dr. Antonio Elias (Assistant Professor, University of Málaga) whose expertise is in Functional Data Analysis, stochastic processes, and FTS model development. His research focuses on time series analysis, high-dimensional data, and statistical learning.
It would be possible to secure funds for a research stay at the University of Málaga.
References: References-Nico-ModFTS [PDF 98KB]
Funding Notes:
This project is open to candidates applying for CSC/Underrepresented Studentships and self-funded candidates
Further information:
How to apply
Entry requirements
Fees and funding
PhD Information Session 2026:
On Wednesday 14 January, we will be holding a short information session about PhD studies in Mathematics at QMUL. For full details about the event, please visit: https://www.qmul.ac.uk/maths/postgraduate/postgraduate-research/phd-information-session-2026/

As one of the UK’s most diverse universities, QMUL fosters an inclusive and supportive academic community.
The School of Mathematical Sciences is committed to the equality of opportunities and to advancing women’s careers. As holders of a Bronze Athena SWAN award, we offer family-friendly benefits and support part-time study.